MLaaS4HEP
Machine Learning as a Service for HEP¶
MLaaS for HEP is a set of Python-based modules to support reading HEP data and stream them to the ML tool of the user's choice. It consists of three independent layers: - Data Streaming layer to handle remote data, see reader.py - Data Training layer to train ML model for given HEP data, see workflow.py - Data Inference layer, see tfaas_client.py
The MLaaS4HEP resopitory can be found here.
The general architecture of MLaaS4HEP looks like this: 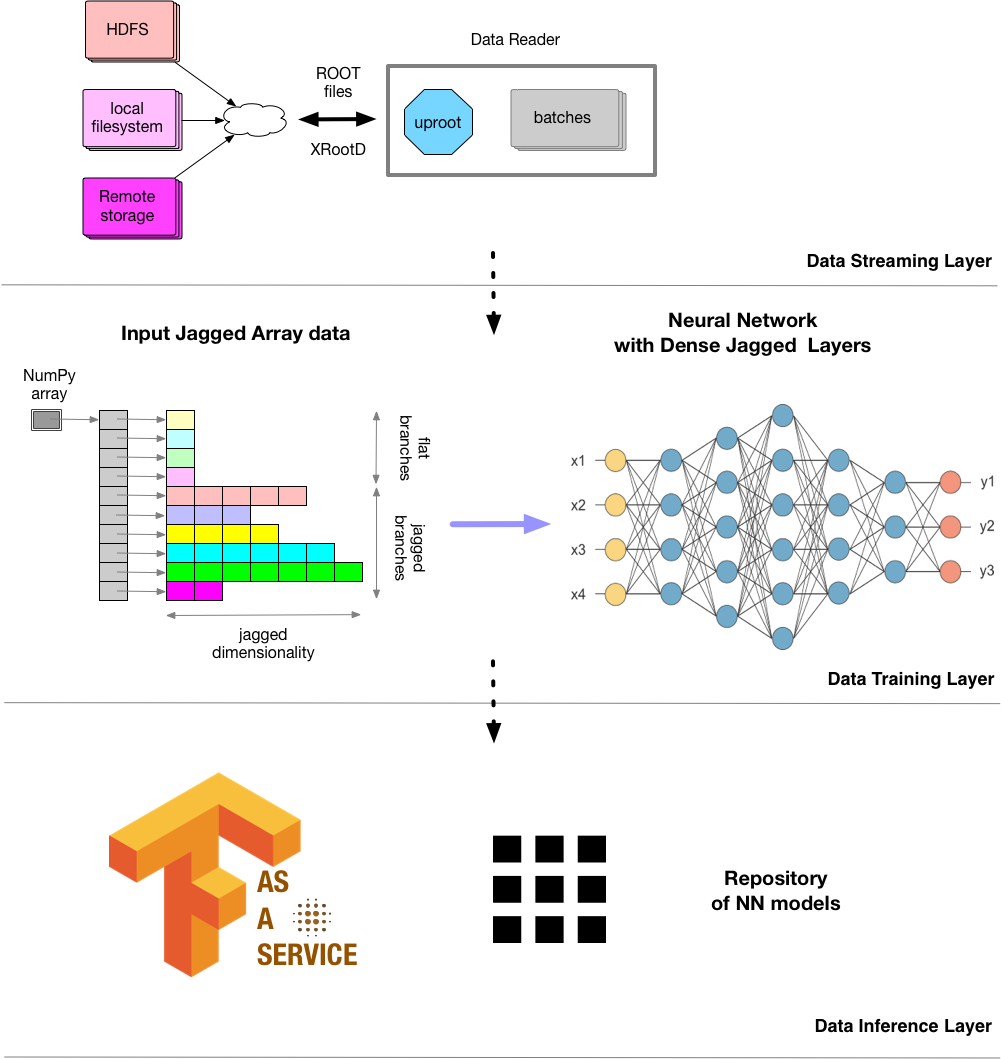
Even though this architecture was originally developed for dealing with HEP ROOT files, we extend it to other data formats. As of right now, following data formats are supported: JSON, CSV, Parquet, and ROOT. All of the formats support reading files from the local file system or HDFS, while the ROOT format supports reading files via the XRootD protocol.
The pre-trained models can be easily uploaded to TFaaS inference server for serving them to clients. The TFaaS documentation can be found here.
Dependencies¶
Here is a list of the dependencies: - pyarrow for reading data from HDFS file system - uproot for reading ROOT files - numpy, pandas for data representation - modin for fast panda support - numba for speeing up individual functions
Installation¶
The easiest way to install and run MLaaS4HEP and TFaaS is to use pre-build docker images
# run MLaaS4HEP docker container
docker run veknet/mlaas4hep
# run TFaaS docker container
docker run veknet/tfaas
Reading ROOT files¶
MLaaS4HEP python repository provides the reader.py module that defines a DataReader class able to read either local or remote ROOT files (via xrootd) in chunks. It is based on the uproot framework.
Basic usage
# setup the proper environment, e.g.
# export PYTHONPATH=/path/src/python # path to MLaaS4HEP python framework
# export PATH=/path/bin:$PATH # path to MLaaS4HEP binaries
# get help and option description
reader --help
# here is a concrete example of reading local ROOT file:
reader --fin=/opt/cms/data/Tau_Run2017F-31Mar2018-v1_NANOAOD.root --info --verbose=1 --nevts=2000
# here is an example of reading remote ROOT file:
reader --fin=root://cms-xrd-global.cern.ch//store/data/Run2017F/Tau/NANOAOD/31Mar2018-v1/20000/6C6F7EAE-7880-E811-82C1-008CFA165F28.root --verbose=1 --nevts=2000 --info
# both of aforementioned commands produce the following output
Reading root://cms-xrd-global.cern.ch//store/data/Run2017F/Tau/NANOAOD/31Mar2018-v1/20000/6C6F7EAE-7880-E811-82C1-008CFA165F28.root
# 1000 entries, 883 branches, 4.113945007324219 MB, 0.6002757549285889 sec, 6.853425235896175 MB/sec, 1.6659010326328503 kHz
# 1000 entries, 883 branches, 4.067909240722656 MB, 1.3497390747070312 sec, 3.0138486148558896 MB/sec, 0.740883937302516 kHz
###total time elapsed for reading + specs computing: 2.2570559978485107 sec; number of chunks 2
###total time elapsed for reading: 1.9500117301940918 sec; number of chunks 2
--- first pass: 1131872 events, (648-flat, 232-jagged) branches, 2463 attrs
VMEM used: 29.896704 (MB) SWAP used: 0.0 (MB)
<__main__.RootDataReader object at 0x7fb0cdfe4a00> init is complete in 2.265552043914795 sec
Number of events : 1131872
# flat branches : 648
CaloMET_phi values in [-3.140625, 3.13671875] range, dim=N/A
CaloMET_pt values in [0.783203125, 257.75] range, dim=N/A
CaloMET_sumEt values in [820.0, 3790.0] range, dim=N/A
More examples about using uproot may be found here and here.
How to train ML models on HEP ROOT data¶
The MLaaS4HEP framework allows to train ML models in different ways: - using full dataset (i.e. the entire amount of events stored in input ROOT files) - using chunks, as subsets of a dataset, which dimension can be chosen directly by the user and can vary between 1 and the total number of events - using local or remote ROOT files.
The training phase is managed by the workflow.py module which performs the following actions: - read all input ROOT files in chunks to compute a specs file (where the main information about the ROOT files are stored: the dimension of branches, the minimum and the maximum for each branch, and the number of events for each ROOT file) - perform the training cycle (each time using a new chunk of events) - create a new chunk of events taken proportionally from the input ROOT files - extract and convert each event in a list of NumPy arrays - normalize the events - fix the Jagged Arrays dimension - create the masking vector - use the chunk to train the ML model provided by the user
A schematic representation of the steps performed in the MLaaS4HEP pipeline, in particular those inside the Data Streaming and Data Training layers, is: 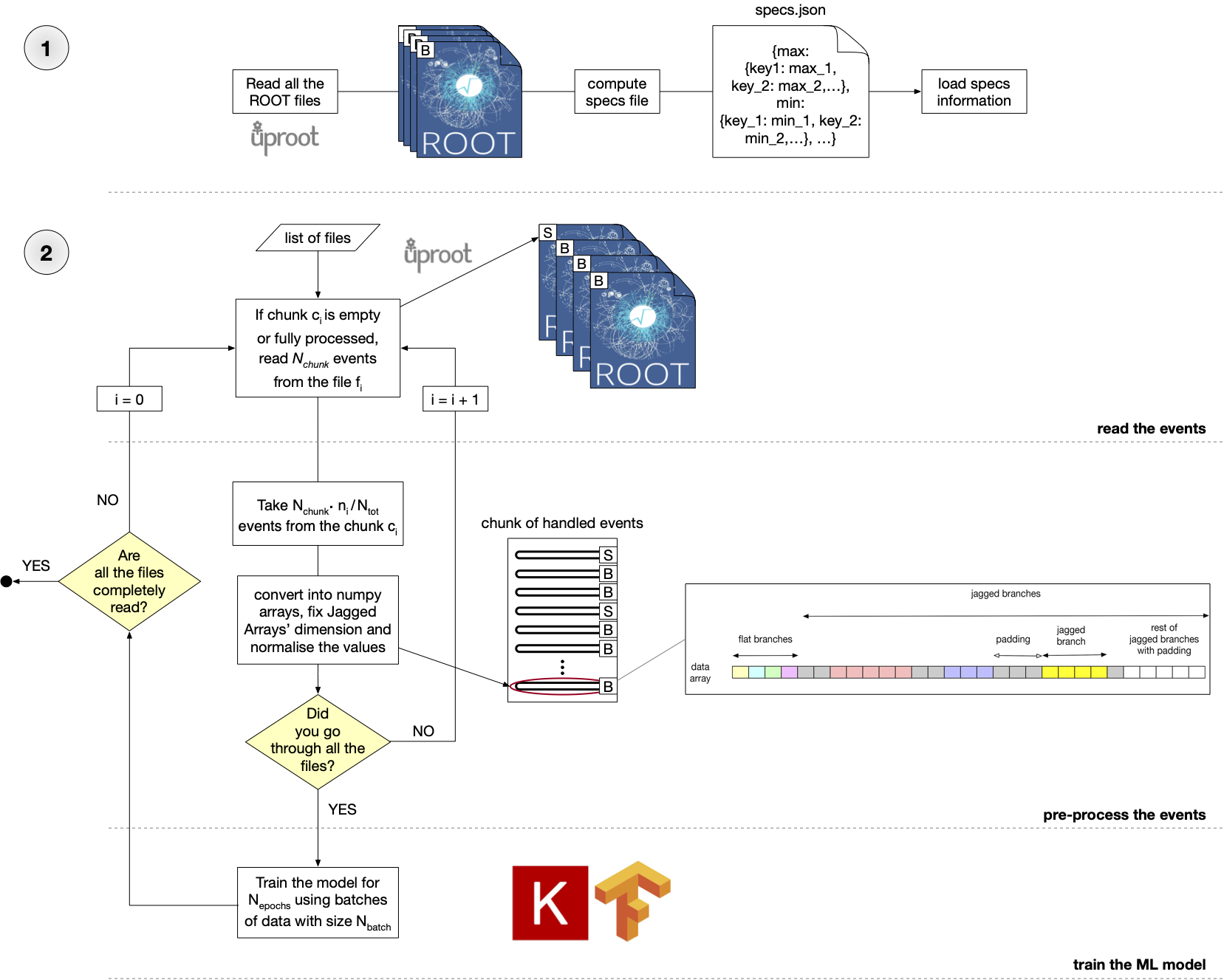
 If the dataset is large and exceed the amount of RAM on the training node, then the user should consider the chunk approach. This allows to train the ML model each time using a different chunk, until the entire dataset is completely read. In this case the user should pay close attention to the ML model convergence, and validate it after each chunk. For more information look at this, this and this. Using different training approach has pros and cons. For instance, training on entire dataset can guarantee the ML model convergence, but the dataset should fits into RAM of the training node. While chunk approach allows to split the dataset to fit in the hardware resources, but it requires proper model evaluation after each chunk training. In terms of training speed, this choice should be faster than training on the entire dataset, since after having used a chunk for training, that chunk is no longer read and used subsequently (this effect is prominent when remote ROOT files are used). Finally, user should be aware of potential divergence of ML model when training last chunk of the dataset and check for bias towards last chunk. For instance, user may implement a K-fold cross validation approach to train on N-1 chunks (i.e. folds in this case) and use one chunk for validation.
If the dataset is large and exceed the amount of RAM on the training node, then the user should consider the chunk approach. This allows to train the ML model each time using a different chunk, until the entire dataset is completely read. In this case the user should pay close attention to the ML model convergence, and validate it after each chunk. For more information look at this, this and this. Using different training approach has pros and cons. For instance, training on entire dataset can guarantee the ML model convergence, but the dataset should fits into RAM of the training node. While chunk approach allows to split the dataset to fit in the hardware resources, but it requires proper model evaluation after each chunk training. In terms of training speed, this choice should be faster than training on the entire dataset, since after having used a chunk for training, that chunk is no longer read and used subsequently (this effect is prominent when remote ROOT files are used). Finally, user should be aware of potential divergence of ML model when training last chunk of the dataset and check for bias towards last chunk. For instance, user may implement a K-fold cross validation approach to train on N-1 chunks (i.e. folds in this case) and use one chunk for validation.
A detailed description of how to use the workflow.py module for training a ML model reading ROOT files from the opendata portal, can be found here. Please see how the user has to provide several information when run the workflow.py module, e.g. the definition of the ML model, and then is task of MLaaS4HEP framework to perform all the training procedure using the ML model provided by the user.
For a complete description of MLaaS4HEP see this paper.