Bayesian Neural Network¶
Usually, neural networks are optimized in order to get a fixed value for the weights and biases which allow the model perform a specific task successfully. In a Bayesian neural network the weights and biases are distributed rather than fixed. This type of model could be treated as an ensemble of many neural networks, train using a Bayesian inference.
Using a Bayesian approach for the neural network training allows the analyzer to estimate the uncertainty and to make the decision of the model more robust against the input data.
Difference between usual NN and BNN¶
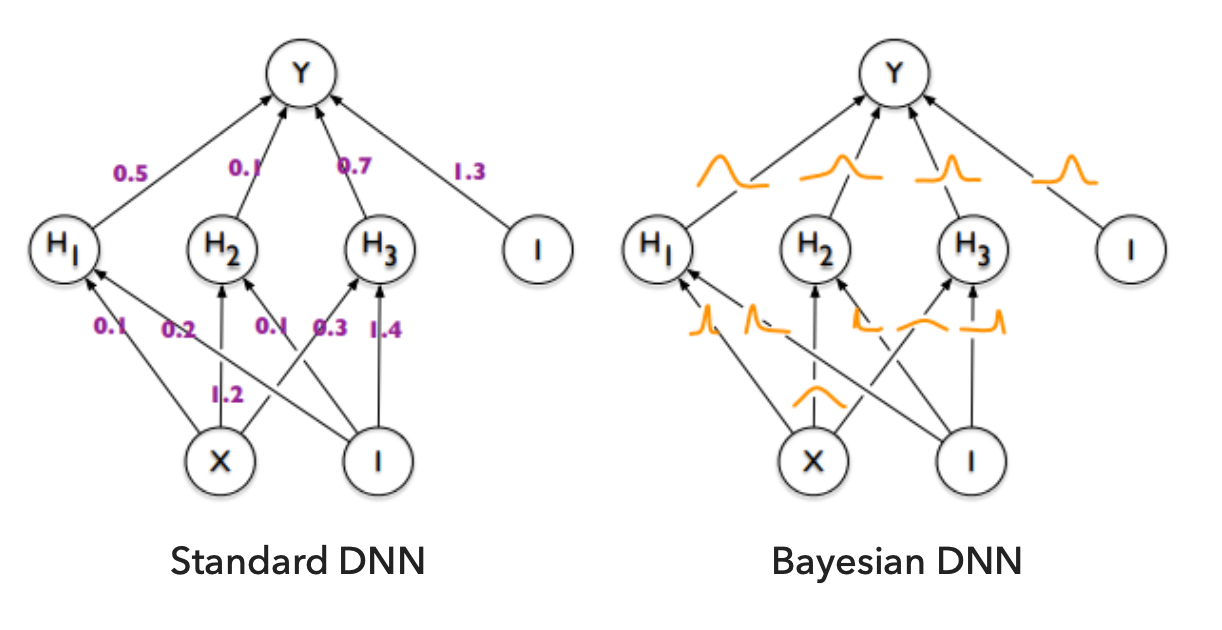
Training of NN and BNN¶
 The parameters
The parameters are optimized in order to minimaze the loss function.
 The process is to learn the probability distributions for weights and biases that maximize the likelihood of getting a high probability for the correct data/label
The process is to learn the probability distributions for weights and biases that maximize the likelihood of getting a high probability for the correct data/label pairs. The parameters of the weight distributions -- mean and standard deviation -- are the results of the loss function optimization.
Training Procedure¶
1. Introduce the prior distribution over model parameter w
2. Compute posterio p(w|D) using Bayesian rule
3. Take the average over the posterior distribution
Prediction of NN and BNN¶

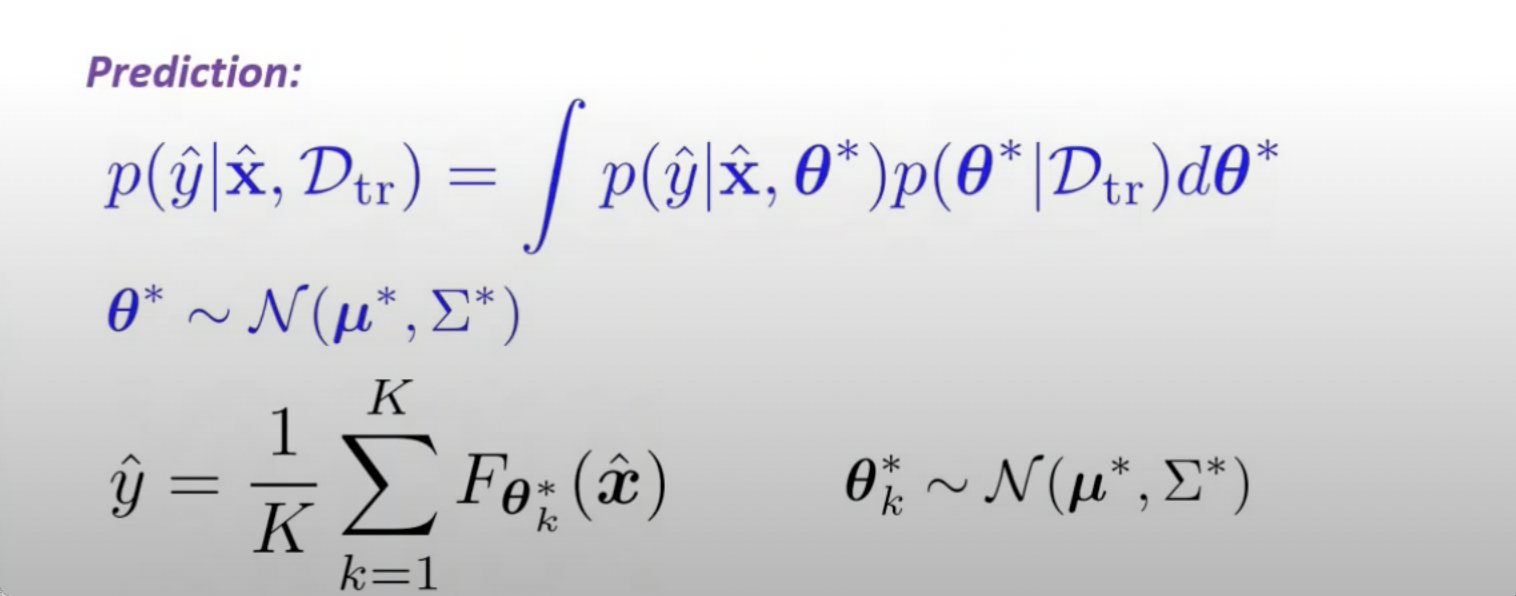
Uncertainty¶
There are two types of BNN uncertainties:
Alletonic - uncertainties due to the lack of knowledge, comes from data or enviroment
Epistemic - uncertainties of the model parameter
Packages¶
Here we will list a few of the machine learning packages which can be used to develop a probabilistic neural network.
1 | |
1 | |
Modules Description:¶
Distribution and sampling¶
Distribution and sampling¶
Example¶
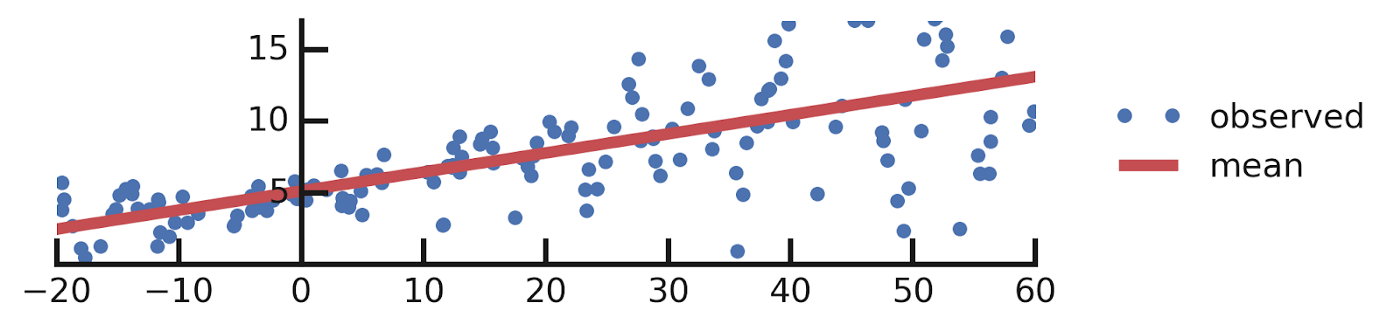
Let's consider simple linear regression as an example and compare it to the Bayesian analog.
Lets consider simple dataset D(x, y) and we want to fit some linear function: y=ax+b+e, where a,b are learnable parameters and e is observation noise.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Let's consider you write your network model in a single tf.function.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
The output of the model:
Variational Autoencoder¶
Generative models can be built using a Bayesian neural network. The variational autoencoder is one popular way to forma generative model.
Let's consider the example of generating the images:
The generating process consist of two steps:
-
Sampling the latent variable from prior distribution
-
Drawing the sample from stochastic process
Objective:
the prior on the latent representation
,
, the variational encoder, and
, the decoder — how likely is the image x given the latent representation z.
Loss¶
Once we define the procedure for the generation process the objective function should be chosen for the optimization process. In order to train the network, we maximize the ELBO (Evidence Lower Bound) objective.
Prior¶
p(z), the prior on the latent representation z,
q(z|x), the variational encoder, and
p(x|z), the decoder — how likely is the image x given the latent representation z.
Encoder and Decoder¶
1 | |
1 | |
Training¶
1 | |
1 | |
Results¶
1 | |
1 | |
Normalizing Flows¶
Defition¶
1 | |
1 | |
Training¶
1 | |
1 | |
Inference¶
1 | |
1 | |
Resources¶
Bayesian NN¶
1. https://arxiv.org/pdf/2007.06823.pdf
2. http://krasserm.github.io/2019/03/14/bayesian-neural-networks/
3. https://arxiv.org/pdf/1807.02811.pdf
Normalizing Flow:¶
1. https://arxiv.org/abs/1908.09257
2. https://arxiv.org/pdf/1505.05770.pdf
Variational AutoEncoder:¶
1. https://arxiv.org/abs/1312.6114
2. https://pyro.ai/examples/vae.html
3. https://www.tensorflow.org/probability/examples/Probabilistic_Layers_VAE