Direct inference with (Q)ONNX Runtime¶
![]()
![]()
Text taken and adopted from the QONNX README.md.
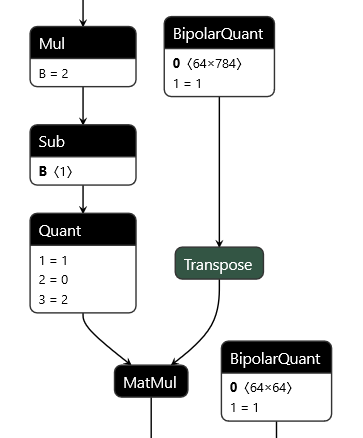
QONNX (Quantized ONNX) introduces three new custom operators -- Quant, BipolarQuant, and Trunc -- in order to represent arbitrary-precision uniform quantization in ONNX. This enables:
- Representation of binary, ternary, 3-bit, 4-bit, 6-bit or any other quantization.
- Quantization is an operator itself, and can be applied to any parameter or layer input.
- Flexible choices for scaling factor and zero-point granularity.
- Quantized values are carried using standard
floatdatatypes to remain ONNX protobuf-compatible.
This repository contains a set of Python utilities to work with QONNX models, including but not limited to:
- executing QONNX models for (slow) functional verification
- shape inference, constant folding and other basic optimizations
- summarizing the inference cost of a QONNX model in terms of mixed-precision MACs, parameter and activation volume
- Python infrastructure for writing transformations and defining executable, shape-inferencable custom ops
- (experimental) data layout conversion from standard ONNX NCHW to custom QONNX NHWC ops