Overfitting
Given that the training experiment has been set up correctly (with some of the most common problems described in before training section), actually few things can go wrong during the training process itself. Broadly speaking, they fall into two categories: overfitting related and optimisation problem related. Both of them can be easily spotted by closely monitoring the training procedure, as will be described in the following.
Overfitting¶
The concept of overfitting (also called overtraining) was previously introduced in inputs section and here we will elaborate a bit more on that. In its essence, overfitting as the situation where the model fails to generalise to a given problem can have several underlying explanations:
The first one would be the case where the model complexity is way too large for a problem and a data set being considered.
Example
A simple example would be fitting of some linearly distributed data with a polynomial function of a large degree. Or in general, when the number of trainable parameters is significantly larger when the size of the training data set.
This can be solved prior to training by applying regularisation to the model, which in it essence means constraining its capacity to learn the data representation. This is somewhat related also to the concept of Ockham's razor: namely that the less complex an ML model, the more likely that a good empirical result is not just due to the peculiarities of the data sample. As of the practical side of regularisation, please have a look at this webpage for a detailed overview and implementation examples.
Furthermore, a recipe for training neural networks by A. Karpathy is a highly-recommended guideline not only on regularisation, but on training ML models in general.
The second case is a more general idea that any reasonable model at some point starts to overfit.
Example
Here one can look at overfitting as the point where the model considers noise to be of the same relevance and start to "focus" on it way too much. Since data almost always contains noise, this makes it in principle highly probable to reach overfitting at some point.
Both of the cases outlined above can be spotted simply by tracking the evolution of loss/metrics on the validation data set . Which means that additionally to the train/test split done prior to training (as described in inputs section), one need to set aside also some fraction of the training data to perform validation throughout the training. By plotting the values of loss function/metric both on train and validation sets as the training proceeds, overfitting manifests itself as the increase in the value of the metric on the validation set while it is still continues to decrease on the training set:
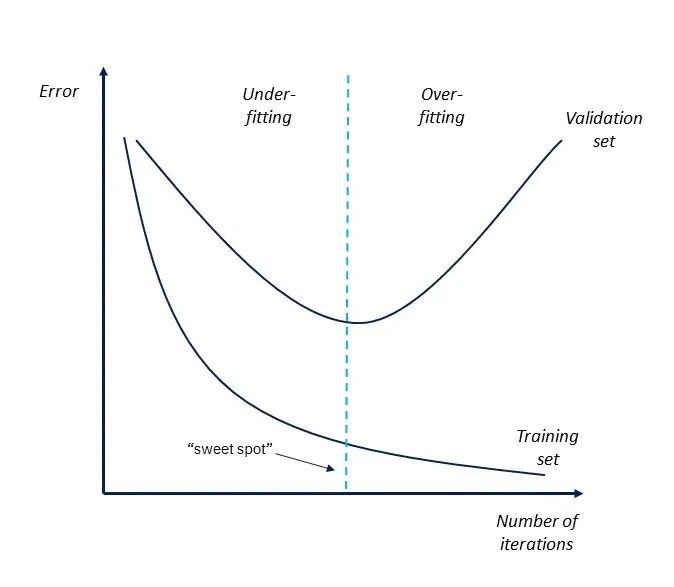
Essentially, it means that from that turning point onwards the model is trying to learn better and better the noise in training data at the expense of generalisation power. Therefore, it doesn't make sense to train the model from that point on and the training should be stopped.
To automate the process of finding this "sweat spot", many ML libraries include early stopping as one of its parameters in the fit() function. If early stopping is set to, for example, 10 iterations, the training will automatically stop once the validation metric is no longer improving for the last 10 iterations.