Features
In the previous section, the data was considered from a general "domain" perspective and in this section a more low level view will be outlined. In particular, an emphasis will be made on features (input variables) as they play a crucial role in the training of any ML model. Essentially being the handle on and the gateway into data for the model, they are expected to reflect the data from the perspective which is important to the problem at hand and therefore define the model performance on the task.
The topic of feature engineering is very extensive and complex to be covered in this section, so the emphasis will be made primarily on the general aspects relevant to the HEP context. Broadly speaking, one should ask themselves the following questions during the data preparation:
- Are features understood?
- Are features correctly modelled?
- Are features appropriately processed?
Understanding¶
Clearly one should motivate for themselves (and then possibly for analysis reviewers) why this exact set of features and not the other one has been selected1. Aside from physical understanding and intuition it would be good if a priori expert knowledge is supplemented by running further experiments.
Here one can consider either studies done prior to the training or after it. As for the former, studying feature correlations (with the target variable as well) e.g. by computing Pearson and/or Spearman correlation coefficients and plotting several histogram/scatter plots could bring some helpful insights. As for the latter, exploring feature importances as the trained model deems it important can boost the understanding of both the data and the model altogether.
Modelling¶
Although seemingly obvious, for the sake of completeness the point of achieving good data/MC agreement should be mentioned. It has always been a must to be checked in a cut-based approach and ML-based one is of no difference: the principle "garbage in, garbage out" still holds.
Example
For example, classical feed-forward neural network is just a continuous function mapping the input space to the output one, so any discrepancies in the input might propagate to the output. In case of boosted decision trees it is also applicable: any (domain) differences in the shape of input (training) distribution w.r.t. true "data" distribution might sizeably affect the construction of decision boundary in the feature space.
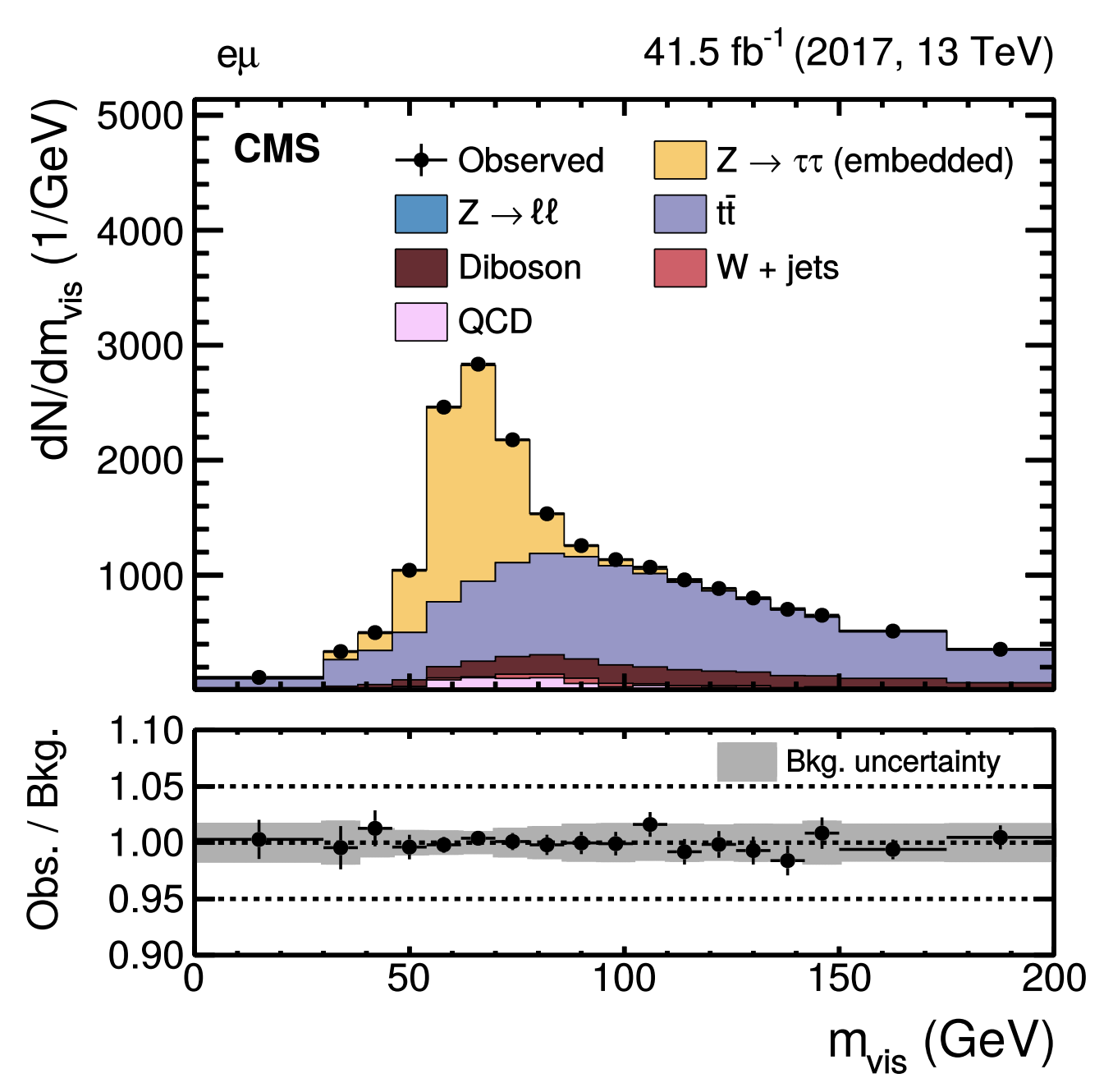
Since features are the handle on the data, checking for each input feature that the ratio of data to MC features' histograms is close to 1 within uncertainties (aka by eye) is one of the options. For a more formal approach, one can perform goodness of fit (GoF) tests in 1D and 2D, checking that as it was used for example in the analysis of Higgs boson decaying into tau leptons.
If the modelling is shown to be insufficient, the corresponding feature should be either removed, or mismodelling needs to be investigated and resolved.
Processing¶
Feature preprocessing can also be understood from a broader perspective of data preprocessing, i.e. transformations which need to be performed with data prior to training a model. Another way to look at this is of a step where raw data is converted into prepared data. That makes it an important part of any ML pipeline since it ensures that a smooth convergence and stability of the training is reached.
Example
In fact, the training process might not even begin (presence of NaN values) or break in the middle (outlier causing the gradients to explode). Furthermore, data can be completely misunderstood by the model which can potentially caused undesirable interpretation and performance (treatment of categorical variables as numerical).
Therefore, below there is a non-exhaustive list of the most common items to be addressed during the preprocessing step to ensure the good quality of training. For a more comprehensive overview and also code examples please refer to a detailed documentation of sklearn package and also on possible pitfalls which can arise at this point.
- Feature encoding
- NaN/inf/missing values2
- Outliers & noisy data
- Standartisation & transformations
Finally, these are the items which are worth considering in the preprocessing of data in general. However, one can also apply transformations at the level of batches as they are passed through the model. This will be briefly covered in the following section.
-
Here it is already assumed that a proper data representation has been chosen, i.e. the way to vectorize the data to form a particular structure (e.g. image -> tensor, social network -> graph, text -> embeddings). Being on its own a whole big topic, it is left for a curious reader to dive into. ↩
-
Depending on the library and how particular model is implemented there, these values can be handled automatically under the hood. ↩